|
Yahoo! WOEID (Where On Earth Identifier) 是Yahoo的一套用于识别地球上不同地址的编号系统。许多网站,包括Twitter都用woeid来识别位置信息。本文主题就是利用scrapy从网上抓取给定国家的woeid 我将要抓取的网站是http://woeid.rosselliot.co.nz/,我们可以在这个网页输入想要查找的地名,可以是国家名,城市名或者邮编。然后在下方的表格中我们就能找到所有含有这个地名的地方。 比如我们想看看China的woeid是多少,那么我们就在输入框中输入 "China", 单击 lookup, 之后的url是http://woeid.rosselliot.co.nz/lookup/china
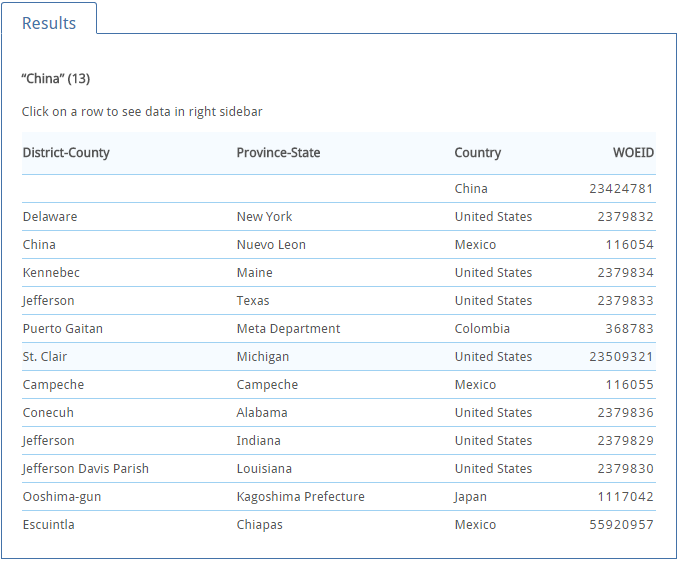
2016.6.23.1.jpg 在 Results 表格中,我们看见下面弹出了13个结果
2016.6.23.2.jpg 非常有趣的是,除了中国叫China以外,在美国竟然有七个地方也叫China,其中一个还是County,而在日本也有一个小地方叫China。
2016.6.23.3.jpg 下面就是写scrapy爬虫来抓取所有国家的woeid。 根据我的需求,这个scrapy爬虫可以分三部分完成: 1. 定义 item 2. 定义 spider 3. 定义 item pipeline item用于存储每一个国家的名字和woeid spider用于发送request并处理返回的response。 item pipeline在scrapy中专门用于储存从spider返回的item。 这里再复述一遍scrapy主要的工作流程: 整个抓取过程开始于一个spider,第一个request就从spider发出。然后通过Engine进入Scheduler,等待发送给Downloader。Downloader处理request并返回response,response会通过Engine被返回给Spider,spider再对response进行处理,处理过程中产生的item会被Engine发送到Item Pipeline进行后续处理,而如果产生了新的request的话,则这个新的request又会被Engine传递给Scheduler。 第一步,ItemItem需要定义在project的 item.py 文件中。 item.py: import scrapyclass WoeidItem(scrapy.Item):origin = scrapy.Field() disctrict = scrapy.Field() state = scrapy.Field() country = scrapy.Field() woeid = scrapy.Field() 这里定义了五个属性。 origin用于存储我们在查找国家时输入的字符串。之所以要这个属性是为了防止万一有的国家没有搜索结果,或者搜索结果和我们输入的字符不太一样,从而方便识别。 district,state,country用于存储每个地点的三个位置信息。由于我们现在的目的是提取每个国家的woeid,所以前两个暂时不会用到。 woeid就用来存储woeid。 第二步,spider# -*- coding: utf-8 -*-import reimport scrapyfrom woeid.items import WoeidItemclass CountryidSpider(scrapy.Spider):name = "countryid"# allowed_domains = ["woeid.rosselliot.co.nz/lookup"] start_urls = ( 'http://woeid.rosselliot.co.nz/lookup/', ) start_url = 'http://woeid.rosselliot.co.nz/lookup/'def parse(self, response):countries = open('countriesoftheworld.txt', 'r') _ = countries.readline() # get rid of column name for country in countries:country = re.sub('[^w|s|\-]|\n', '', country) # obay the input form yield scrapy.Request( url=self.start_url+country, callback=self.after_input ) def after_input(self, response):item = WoeidItem() # get the input name of country try:item['origin'] = response.xpath('(//form/div)[2]/input/@value').extract()[0]except IndexError:item['origin'] = response.url[37:]# get the woeid if response.xpath('//table').extract():item['woeid'] = response.xpath('(//table/tr)[1]/@data-woeid').extract()[0]print(response.url[37:], item['woeid']) else:item['woeid'] = ''print('something wrong with getting the woeid for: '+item['origin']) # get the country name in the website if item['woeid'] != '':item['country'] = response.xpath('(//table/tr)[1]/@data-country').extract()[0].encode('utf-8') else:item['country'] = ''yield item首先,由于我们要抓取的网页就是最普通的网页,因此只需要让spider继承scrapy.Spider就好。 parse()方法: 我的思路是,在这里先打开事先存储好的国家列表,如下图
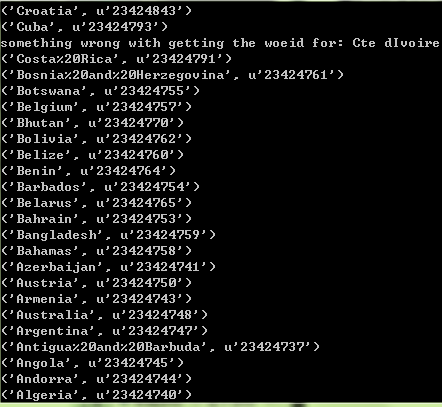
2016.6.23.4.jpg 然后对国家名进行迭代,对每个国家名,yield一个request,当传回response后,用after_input方法进行处理。 这里我并没有用FormRequest来提交填写的数据,因为这个网页仅仅是通过url来区分不同的国家,所以只要把国家名添加到url后面,然后直接访问这个url就好。就比如: http://woeid.rosselliot.co.nz/lookup/china 此处对国家名用正则表达式进行了处理,因为在我下载下来的国家列表中,有一些带有特殊符号,而在lookup时,输入的字符只能为字母数字下划线与横线。所以这段正则表达式的含义就是将所有不是字母数字下划线横线以及空格的字符替换成空。 after_input()方法: 这个方法用于处理返回的response,并生成item。 首先是"origin"属性,因为当时写的时候出过一点错,为了保险起见,用两种方式赋值。先通过输入框寻找,如果失败了则直接从url中截取。之所以不直接用url是因为由于编码的原因url中所有空格都是%20,而我对这些编码还不太熟悉。 然后就是提取woeid,如果我们的搜索有结果的话,在网页中是会有一个table tag来显示结果的,所以就用是否存在table tag来作为搜索成功与否的判断条件就好。如果没有结果,则打印一行字进行提示。 最后就是输入country,如果有结果的话,则country在woeid的系统中的标准写法(包括大小写的变化)就可以在table中找到,如果没有结果则为空。 最后生成 item。这个item会被Engine返回给item pipeline进行处理。 第三步,pipelines在pipelines.py中定义 WoeidPipeline 来处理spider返回的item。 import csvclass WoeidPipeline(object):def __init__(self):print('init') self.csv_id = open('data/country_id.csv', 'a') self.csv_noid = open('data/country_noid.csv', 'a') self.id_writer = csv.writer(self.csv_id, delimiter=',',lineterminator='') self.noid_writer = csv.writer(self.csv_noid, delimiter=',', lineterminator='') def open_spider(self, spider):print('open spider') self.id_writer.writerow(["original name", "country", "woeid"]) self.noid_writer.writerow(["original name"]) def process_item(self, item, spider):print('process_item',item['origin'],item['woeid'],item['country']) if item['woeid'] != '':self.id_writer.writerow([item['origin'], item['country'], item['woeid']]) else:self.noid_writer.writerow([item['origin']]) return item首先,在初始化时打开两个csv文件并声明两个对应的writer。在这一个细节就是要设定lineterminator=''否则 .csv 文件中每条记录之间都会有一个空行。 其次,open_spider()方法仅在spider开始工作前调用一次,用于一些准备操作,在这我要做的就是给两个文件先写上列名。 然后,是process_item方法,每个返回到pipeline的item都要进入这个方法。在这里我做的就是,先打印一下传入的内容,然后依woeid是否为空的条件,决定传入哪个文件。 最后还没完,如果要启用pipeline,还需要在settings.py中进行相关设置才行 settings.py # Configure item pipelines# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = { 'woeid.pipelines.WoeidPipeline': 300,}其中的数字代表各个部分的执行次序,由于在这我们暂时只有一个pipeline而已所以大小是多少并没有关系。 另外在下载国家名是,一个细节是科特迪瓦,Cote D'Ivoire,这个是法语名,有特殊字符 'o + ^' 当经过正则表达式处理之后就不是完整的名字了。而在woeid中科特迪瓦真正的名字是英文名 Ivory Coast,与法语名的含义是一样的:象牙海岸。 另外,Congo 与 Democratic Republic of Congo 是两个国家,刚果金,刚果布。类似韩国和北朝鲜。 在运行spider之后,结果如下
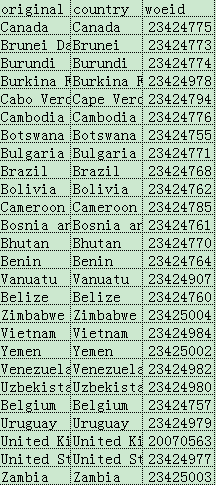
2016.6.23.5.jpg csv文件如下
2016.6.23.6.jpg 而查找失败的科特迪瓦法语名也存储在了country_noid.csv中。
2016.6.23.7.jpg |